¿Qué son los contenedores en la computación en la nube?

Desde que Docker apareció en escena en 2013, la popularidad de los contenedores se ha disparado. Muchas empresas ya han integrado contenedores en sus flujos de trabajo porque les permite implementar, distribuir, administrar y escalar fácilmente su software.
En este artículo, explicaremos qué son los contenedores en la computación en la nube. Hablaremos sobre los beneficios de usar contenedores, sus casos de uso, los compararemos con máquinas virtuales y veremos Docker y Kubernetes. Por último, le enseñaremos cómo codificar, dockerizar e implementar una aplicación web en los Back4app Containers, ¡totalmente gratis!
Contents
- 1 Definición de contenedor
- 2 Beneficios de usar Contenedores
- 3 Casos de uso de contenedores
- 4 Contenedores vs. máquinas virtuales
- 5 Docker y Kubernetes
- 6 Desarrollo de una aplicación utilizando arquitectura basada en contenedores
- 7 Conclusión
- 8 Preguntas frecuentes
- 9 ¿Qué es un contenedor?
- 10 ¿Cuáles son los beneficios de usar contenedores?
- 11 ¿Cuál es la diferencia entre contenedores y máquinas virtuales?
- 12 ¿Cuál es la diferencia entre Docker y Kubernetes?
- 13 ¿Cómo desarrollar una aplicación utilizando una arquitectura basada en contenedores?
Definición de contenedor
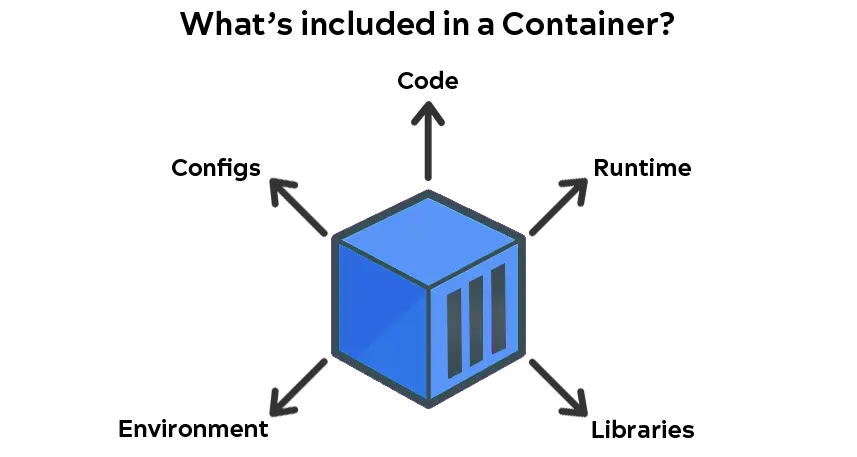
Un contenedor es un paquete ejecutable independiente que incluye todo lo necesario para ejecutar una aplicación: código, tiempo de ejecución, bibliotecas, variables de entorno y archivos de configuración. Lo increíble de las aplicaciones en contenedores es que pueden ejecutarse en cualquier lugar, desde su entorno de desarrollo local hasta nubes públicas, etc. Los contenedores son de tamaño pequeño, eficientes y permiten un aislamiento eficaz.
Beneficios de usar Contenedores
El uso de contenedores tiene varios beneficios. Veamos algunos de ellos.
Eficiencia
Los contenedores requieren menos recursos del sistema que los servidores tradicionales o las máquinas virtuales porque no incluyen una imagen del sistema operativo. Eso los hace extremadamente eficientes, de tamaño pequeño (generalmente medido en MB) y le permite ejecutar una cantidad significativa de aplicaciones en un servidor.
Aislamiento de aplicaciones
Los contenedores aíslan la aplicación y sus dependencias del sistema host. Al mismo tiempo, pueden compartir el núcleo del sistema operativo y los recursos del sistema, como la CPU, la memoria, el almacenamiento y la red.
Portabilidad
El software en contenedores puede ejecutarse y comportarse de la misma manera en prácticamente cualquier máquina que tenga instalado el motor contenedor. Esto facilita la implementación y el traslado de aplicaciones entre diferentes entornos y elimina el problema de “funciona en mi máquina”.
Separación de responsabilidad
Los contenedores permiten la separación de responsabilidades al dividir las tareas y responsabilidades entre los desarrolladores y los equipos de operaciones de TI. Los desarrolladores son responsables de crear y mantener el código y las dependencias de la aplicación, mientras que los equipos de operaciones de TI se enfocan en implementar y administrar los contenedores y la infraestructura subyacente.
Desarrollo de aplicaciones más rápido
La contenedorización facilita el desarrollo, la prueba, la gestión y la distribución de software. Los contenedores se pueden integrar fácilmente con los sistemas CI/CD, lo que puede acelerar en gran medida el desarrollo de software y el proceso de envío.
Fácil escalado
Las aplicaciones en contenedores en combinación con una plataforma de orquestación como Kubernetes pueden escalar fácilmente bajo demanda. Esto le permite a su negocio acomodar grandes cargas de trabajo mientras minimiza los costos.
Casos de uso de contenedores
La tecnología de contenedores tiene muchos casos de uso para los desarrolladores, así como para los equipos de operaciones de TI.
Desarrollo nativo de contenedores
El desarrollo nativo de contenedores es un enfoque de desarrollo de software que aprovecha los contenedores como un bloque de construcción principal. En el desarrollo nativo de contenedores, las aplicaciones se empaquetan como contenedores y se ejecutan en un entorno en contenedores. Este enfoque de desarrollo le brinda todas las ventajas interesantes que los contenedores tienen para ofrecer.
Integración Continua y Entrega Continua (CI/CD)
En una canalización de CI/CD, los contenedores se usan para empaquetar aplicaciones y ejecutar pruebas automatizadas, lo que hace posible probar e implementar aplicaciones de manera consistente y repetible. Los contenedores se pueden crear, probar e implementar fácilmente como parte de la canalización de CI/CD, lo que reduce el riesgo de errores y mejora la eficiencia general del proceso de desarrollo de software.
Microservicios
Los contenedores se pueden usar para desarrollar aplicaciones que siguen una arquitectura de microservicio. Con los contenedores, puede dividir fácilmente su aplicación monolítica en una colección de servicios detallados y poco acoplados que se ejecutan en diferentes contenedores.
Entorno de desarrollo
Los contenedores facilitan que los equipos de desarrolladores configuren rápidamente sus entornos de desarrollo. Proporcionan entornos de desarrollo consistentes independientemente de su sistema operativo anfitrión y bibliotecas anfitrionas.
Procesos por lotes
Los procesos por lotes se pueden contener e implementar fácilmente en la nube. Cada tarea se empaqueta como una imagen de contenedor individual y se ejecuta como una instancia de contenedor separada. Esto permite una utilización eficiente de los recursos, ya que cada tarea se ejecuta en su propio entorno y no interfiere con otras tareas.
Contenedores vs. máquinas virtuales
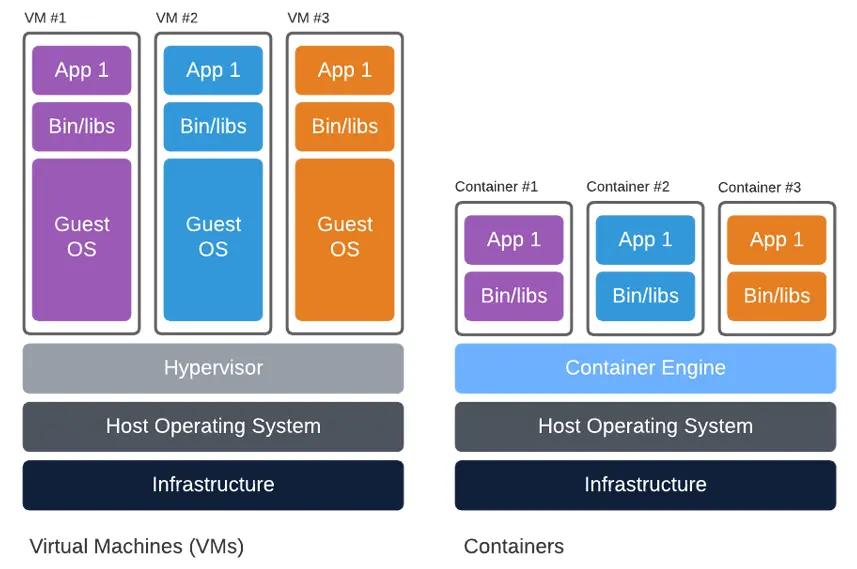
Los contenedores y las máquinas virtuales son dos enfoques diferentes para la virtualización. Aunque tienen algunas similitudes, son bastante diferentes.
Las máquinas virtuales (VM) son una abstracción del hardware físico. Nos permiten convertir un servidor en varios servidores. Cada una de las máquinas virtuales tiene su propio sistema operativo y generalmente es administrada por un hipervisor. Las máquinas virtuales son adecuadas para ejecutar múltiples aplicaciones (en el mismo servidor), aplicaciones monolíticas y aplicaciones que requieren un alto grado de aislamiento y seguridad. Su inconveniente es que tienden a ocupar mucho espacio y pueden ser bastante lentos para arrancar.
Los contenedores, por otro lado, están virtualizados a nivel del sistema operativo. Ocupan menos espacio ya que comparten el mismo kernel de Linux, son más eficientes, arrancan más rápido, son altamente escalables y pueden manejar más aplicaciones. Los contenedores son administrados por un motor contenedor. Sus principales casos de uso, en contraste con las máquinas virtuales, son los microservicios y las aplicaciones que deben ser portátiles, ligeras y escalables.
También es posible combinar contenedores y máquinas virtuales para obtener los beneficios de ambos.
Docker y Kubernetes
Dos de las herramientas más populares para trabajar con contenedores son Docker y Kubernetes. Expliquemos cómo funcionan y veamos sus diferencias.
Docker es un proyecto de código abierto basado en Linux que se utiliza para automatizar la implementación y la gestión de aplicaciones en contenedores ligeros. Esto permite que las aplicaciones en contenedores funcionen de manera eficiente en diferentes entornos. En estos días, Docker se puede encontrar en casi cualquier lugar, desde máquinas Linux hasta grandes proveedores de nube, etc.
Las alternativas de Docker más populares son Podman, LXD y containerd.
Kubernetes (K8s) es un sistema de orquestación de contenedores de código abierto para automatizar la implementación, el escalado y la administración de aplicaciones en contenedores. Desde su lanzamiento en 2014, se ha convertido en el estándar de facto para implementar y operar aplicaciones en contenedores en entornos de nube. Los beneficios de Kubernetes incluyen escalabilidad, alta disponibilidad, operaciones automatizadas, abstracción de infraestructura y monitoreo de salud.
Otras plataformas de orquestación incluyen: AWS ECS, Nomad y Red Hat OpenShift.
Entonces, ¿cuál es la diferencia entre Docker y Kubernetes? Bueno, en términos simples, Docker nos permite empaquetar y distribuir aplicaciones dentro de contenedores, mientras que Kubernetes facilita que varios contenedores funcionen en armonía entre sí.
Desarrollo de una aplicación utilizando arquitectura basada en contenedores
En esta sección del tutorial, crearemos, dockerizaremos e implementaremos una API REST simple para Back4app.
¿Qué es Back4app Containers?
Back4app Containers es una plataforma gratuita de código abierto para implementar y escalar aplicaciones en contenedores distribuidos globalmente en una infraestructura de nube.
Le permite concentrarse en su software y enviarlo más rápido sin tener que preocuparse por DevOps. La plataforma está estrechamente integrada con GitHub, tiene un sistema de CI/CD incorporado y le permite poner en marcha su aplicación en cuestión de minutos.
¿Por qué usar Back4app Containers?
- Se integra bien con GitHub
- Despliegues sin tiempo de inactividad
- Fácil de usar y tiene un nivel gratuito
- Excelente atención al cliente
Introducción al proyecto
Construiremos una API REST simple que servirá como una lista de observación de películas. La aplicación web permitirá operaciones CRUD básicas como agregar una película, eliminar una película, etc. Para crear la API, usaremos el marco Flask. Por último, dockerizaremos el proyecto y demostraremos lo fácil que es implementarlo en Back4app Containers.
Requisitos previos
- Experiencia con el marco Flask
- Comprensión básica de Docker y contenedores.
- Capacidad para usar Git y GitHub
Aplicación de código
Los siguientes pasos requerirán que tenga Python instalado. Si aún no tiene Python instalado, descárguelo.
Inicialización del proyecto
Primero, cree un directorio dedicado para su aplicación y navegue hasta él:
$ mkdir flask-watchlist
$ cd flask-watchlistA continuación, cree un nuevo entorno virtual y actívelo:
$ python3 -m venv venv && source venv/bin/activateYa que vamos a usar Flask como nuestro marco, tenemos que instalarlo:
$ (venv) pip install Flask==2.2.2Cree la app.py con los siguientes contenidos:
# app.py
from flask import Flask
app = Flask(__name__)
app.config['JSON_SORT_KEYS'] = False
@app.route('/')
def index_view():
return {
'detail': '¡Hola, mundo!'
}Este código inicializa Flask y crea un punto final simple que devuelve un mensaje.
Ejecute el servidor con:
$ flask runVaya a http://localhost:5000/ y debería ver un mensaje que diga ¡Hola, mundo!.
Base de datos
Para la base de datos, usaremos SQLite. SQLite es un sistema de gestión de base de datos relacional integrado y sin servidor. Para simplificar el trabajo con la base de datos, instalaremos Flask-SQLAlchemy, una extensión para Flask que agrega soporte para SQLAlchemy a su aplicación.
Instálelo ejecutando:
$ (venv) pip install Flask-SQLAlchemy==3.0.3A continuación, navegue hasta la parte superior de app.py y cámbielo así para inicializar la base de datos:
# app.py
db = SQLAlchemy()
app = Flask(__name__)
app.config['JSON_SORT_KEYS'] = False
app.config['SECRET_KEY'] = '5b3cd5b80eb8b217c20fb37074ff4a33'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///default.db"
db.init_app(app)No se olvide de la importación:
from flask_sqlalchemy import SQLAlchemyA continuación, definamos nuestros modelos de base de datos.
Dado que estamos creando una aplicación de lista de observación de películas simple, solo necesitaremos un modelo. Defina el modelo Movie así:
# app.py
class Movie(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(128), nullable=False)
release_date = db.Column(db.Date(), nullable=False)
is_watched = db.Column(db.Boolean, default=False)
watched_at = db.Column(db.DateTime, default=None, nullable=True)
def as_dict(self):
return {c.name: getattr(self, c.name) for c in self.__table__.columns}
def __repr__(self):
return '<Movie %r>' % self.titlePara inicializar y llenar nuestra base de datos, crearemos un script de Python simple. Navegue a la raíz de su proyecto y cree un nuevo archivo llamado init_db.py con los siguientes contenidos:
# init_db.py
from datetime import date
from app import db, app
from app import Movie
with app.app_context():
db.create_all()
if Movie.query.count() == 0:
movies = [
Movie(title='Fight Club', release_date=date(1999, 9, 15)),
Movie(title='The Matrix', release_date=date(1999, 3, 31)),
Movie(title='Donnie Darko', release_date=date(2001, 1, 19)),
Movie(title='Inception', release_date=date(2010, 7, 16)),
]
for movie in movies:
db.session.add(movie)
db.session.commit()Lo último que tenemos que hacer es ejecutar el script:
$ (venv) python init_db.pyEsto crea la base de datos, las tablas de la base de datos y las llena. El archivo de la base de datos se colocará en la carpeta de la instancia.
Puntos finales de la API
Nuestra aplicación web tendrá los siguientes puntos finales:
/devuelve información básica de la API/api/devuelve la lista de las películas/api/create/agrega una nueva película a la lista de seguimiento/api/<movie_id>/devuelve detalles de una película específica/api/watch/<movie_id>/marca la película como vista
Continúe y defina los puntos finales en la parte inferior de app.py:
# app.py
@app.route('/')
def index_view():
return {
'name': 'flask-watchlist',
'description': 'a simple app for tracking the movies you want to watch',
'version': 1.1,
}
@app.route('/api/')
def list_view():
json = [movie.as_dict() for movie in Movie.query.all()]
return jsonify(json)
@app.route('/api/<int:movie_id>/', methods=['GET', 'DELETE'])
def detail_view(movie_id):
movie = db.get_or_404(Movie, movie_id)
if request.method == 'DELETE':
db.session.delete(movie)
db.session.commit()
return {
'detail': 'Movie has been successfully deleted.'
}
else:
return movie.as_dict()
@app.route('/api/create/', methods=['POST'])
def create_view():
title = request.form.get('title')
release_date = request.form.get('release_date', type=float)
if title is None or release_date is None:
return {
'detail': 'Please provide the title and release_date.'
}, 400
movie = Movie(title=title, release_date=datetime.fromtimestamp(release_date))
db.session.add(movie)
db.session.commit()
return movie.as_dict()
@app.route('/api/watch/<int:movie_id>/')
def watch_view(movie_id):
movie = db.get_or_404(Movie, movie_id)
if movie.is_watched:
return {
'detail': 'Movie has already been watched.'
}, 400
movie.is_watched = True
movie.watched_at = datetime.now()
db.session.commit()
return movie.as_dict()No se olvide de las importaciones:
from datetime import datetime
from flask import request, jsonifyGenial, nuestra aplicación ya está más o menos completa. Ejecute el servidor de desarrollo:
$ (venv) flask runPruebe si puede obtener la lista de películas:
$ (venv) curl http://localhost:5000/api/ | jq '.'
[
{
"id": 1,
"title": "Fight Club",
"release_date": "Wed, 15 Sep 1999 00:00:00 GMT",
"is_watched": false,
"watched_at": null
},
{
"id": 2,
"title": "The Matrix",
"release_date": "Wed, 31 Mar 1999 00:00:00 GMT",
"is_watched": false,
"watched_at": null
},
...
]Gunicorn
El servidor de desarrollo Flask no es apropiado para la producción, así que intercambiémoslo con Gunicorn. Gunicorn o “Unicornio verde” es un servidor HTTP Python WSGI listo para producción para Unix.
Instálelo ejecutando:
$ (venv) pip install gunicorn==20.1.0Después de que se haya instalado el paquete, puede iniciar su servidor WSGI de la siguiente manera:
$ (venv) gunicorn -w 2 -b 0.0.0.0:5000 app:app
[INFO] Starting gunicorn 20.1.0
[INFO] Listening at: http://0.0.0.0:5000 (1)
[INFO] Using worker: sync
[INFO] Booting worker with pid: 7
[INFO] Booting worker with pid: 8Tenga en cuenta que este comando solo funciona en sistemas operativos basados en UNIX.
Esto iniciará dos trabajadores de Gunicorn y expondrá su aplicación a Internet. Para acceder a la aplicación, abra su navegador web favorito y vaya a http://localhost:5000.
requirements.txt
Lo último que debemos hacer antes de dockerizar nuestra aplicación es crear un archivo requisitos.txt. El archivo requirements.txt se utiliza para especificar las dependencias del proyecto.
La forma más fácil de generarlo es ejecutando:
$ (venv) pip freeze > requirements.txtDockerizando la aplicación
Los siguientes pasos requerirán que tenga Docker instalado. La forma más fácil de instalar Docker es descargando Docker Desktop.
Para verificar que tiene Docker instalado, ejecute:
$ docker --version
Docker version 20.10.22, build 3a2c30bDockerfile
Para dockerizar nuestra aplicación usaremos un Dockerfile. Un Dockerfile es un archivo de texto sin formato que nos permite definir la imagen base, el entorno, las variables ambientales, los comandos, la configuración de red, los volúmenes, etc.
Cree un Dockerfile en la raíz de su proyecto con los siguientes contenidos:
# syntax=docker/dockerfile:1.4
FROM --platform=$BUILDPLATFORM python:3.10-alpine
# set the working directory
WORKDIR /app
# set environmental variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# install the requirements
COPY requirements.txt /app
RUN --mount=type=cache,target=/root/.cache/pip \
pip3 install -r requirements.txt
# copy the code to the container
COPY . .
# initialize the database (create DB, tables, populate)
RUN python init_db.py
# expose
EXPOSE 5000/tcp
# entrypoint command
CMD ["gunicorn", "-w", "2", "-b", "0.0.0.0:5000", "app:app"]- Usamos
python:3.10-alpinecomo imagen base. - Establecer
PYTHONDONTWRITEBYTECODEen1hace que Python ya no escriba archivos .pyc en el disco. - Establecer
PYTHONUNBUFFEREDen1garantiza que los flujos de salida de Python se envíen directamente a la terminal.
Para obtener más información sobre cómo escribir Dockerfiles, consulte la referencia de Dockerfile.
.dockerignore
Antes de que Docker cree una imagen, busque un archivo .dockerignore. Un archivo .dockerignore nos permite definir qué archivos no queremos que se incluyan en la imagen. Esto puede reducir considerablemente el tamaño de la imagen. Funciona de manera similar a un archivo .gitignore.
Cree un archivo .dockerignore en la raíz del proyecto con el siguiente contenido:
# .dockerignore
.git/
instance/
__pycache__/
.idea/Asegúrese de agregar cualquier directorio o archivo adicional que desee excluir.
Compile y ejecute la imagen
Avanzando, construyamos y etiquetemos nuestra imagen de Docker.
$ docker build -t flask-watchlist:1.0 .
[+] Building 11.1s (15/15) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 32B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 34B 0.0s
=> resolve image config for docker.io/docker/dockerfile:1.4 0.5s
=> CACHED docker-image://docker.io/docker/dockerfile:1.4@sha256:9ba7531a0dbc 0.0s
=> [internal] load build definition from Dockerfile 0.0s
=> [internal] load .dockerignore 0.0s
=> [internal] load metadata for docker.io/library/python:3.10-alpine 0.5s
=> [stage-0 1/6] FROM docker.io/library/python:3.10-alpine@sha256:da5ab5e911253dfb 0.0s
=> [internal] load build context 0.3s
=> => transferring context: 182.45kB 0.2s
=> CACHED [stage-0 2/6] WORKDIR /app 0.0s
=> [stage-0 3/6] COPY requirements.txt /app 0.0s
=> [stage-0 4/6] RUN --mount=type=cache,target=/root/.cache/pip
pip3 install -r requirements.txt 7.2s
=> [stage-0 5/6] COPY . . 0.3s
=> [stage-0 6/6] RUN python init_db.py 1.5s
=> exporting to image 0.3s
=> => exporting layers 0.3s
=> => writing image sha256:2671ccb7546a0594807c721a0600a 0.0s
=> => naming to docker.io/library/flask-watchlist:1.0 Si enumera las imágenes, debería ver nuestra nueva imagen:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flask-watchlist 1.0 7bce66230eb1 8 hours ago 110MBPor último, use la imagen para activar un nuevo contenedor Docker:
$ docker run -it -p 5000:5000 flask-watchlist:1.0
[2023-02-02 20:08:57 +0000] [1] [INFO] Starting gunicorn 20.1.0
[2023-02-02 20:08:57 +0000] [1] [INFO] Listening at: http://0.0.0.0:5000 (1)
[2023-02-02 20:08:57 +0000] [1] [INFO] Using worker: sync
[2023-02-02 20:08:57 +0000] [7] [INFO] Booting worker with pid: 7
[2023-02-02 20:08:57 +0000] [8] [INFO] Booting worker with pid: 8Puede usar
-dpara iniciar el contenedor Docker en modo separado. Lo que significa que el contenedor se ejecuta en el fondo de su terminal y no recibe entrada ni muestra salida.
¡Bien hecho, su aplicación ahora se ejecuta en un contenedor! Navegue a http://localhost:5000 y debería obtener la siguiente respuesta:
{
"name": "flask-watchlist",
"description": "a simple app for tracking the movies you want to watch",
"version": 1
}GitHub
Para implementar la aplicación en Back4app Containers, deberá cargar su código fuente en un repositorio de GitHub. Continúe y cree un nuevo repositorio en GitHub, agregue el control remoto, agregue .gitignore y confirme su código. Una vez que su código esté en GitHub, avance al siguiente paso.
Implementar aplicación en Back4app Containers
Los siguientes pasos requerirán que tengas una cuenta Back4app. Si ya lo tiene, inicie sesión;de lo contrario, regístrese para obtener la cuenta gratuita.
Para trabajar con Back4app primero necesitamos crear una aplicación. Al iniciar sesión en su tablero, verá la lista de sus aplicaciones. Haga clic en “Crear una nueva aplicación” para crear una nueva aplicación.
A continuación, seleccione “Contenedores como servicio”.
Si aún no lo ha hecho, conecte su GitHub a Back4app e importe los repositorios que le gustaría implementar. Una vez que su GitHub esté conectado, sus repositorios se mostrarán en la tabla.
Elija el repositorio que le gustaría implementar haciendo clic en “Seleccionar”.
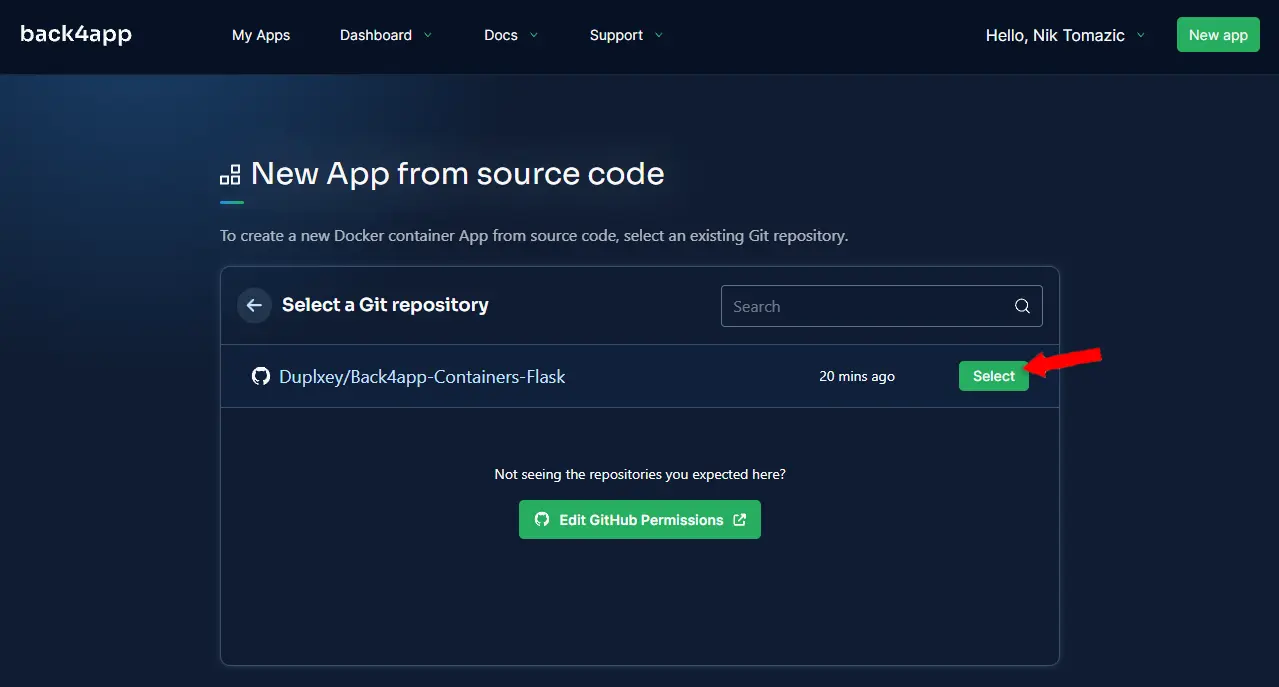
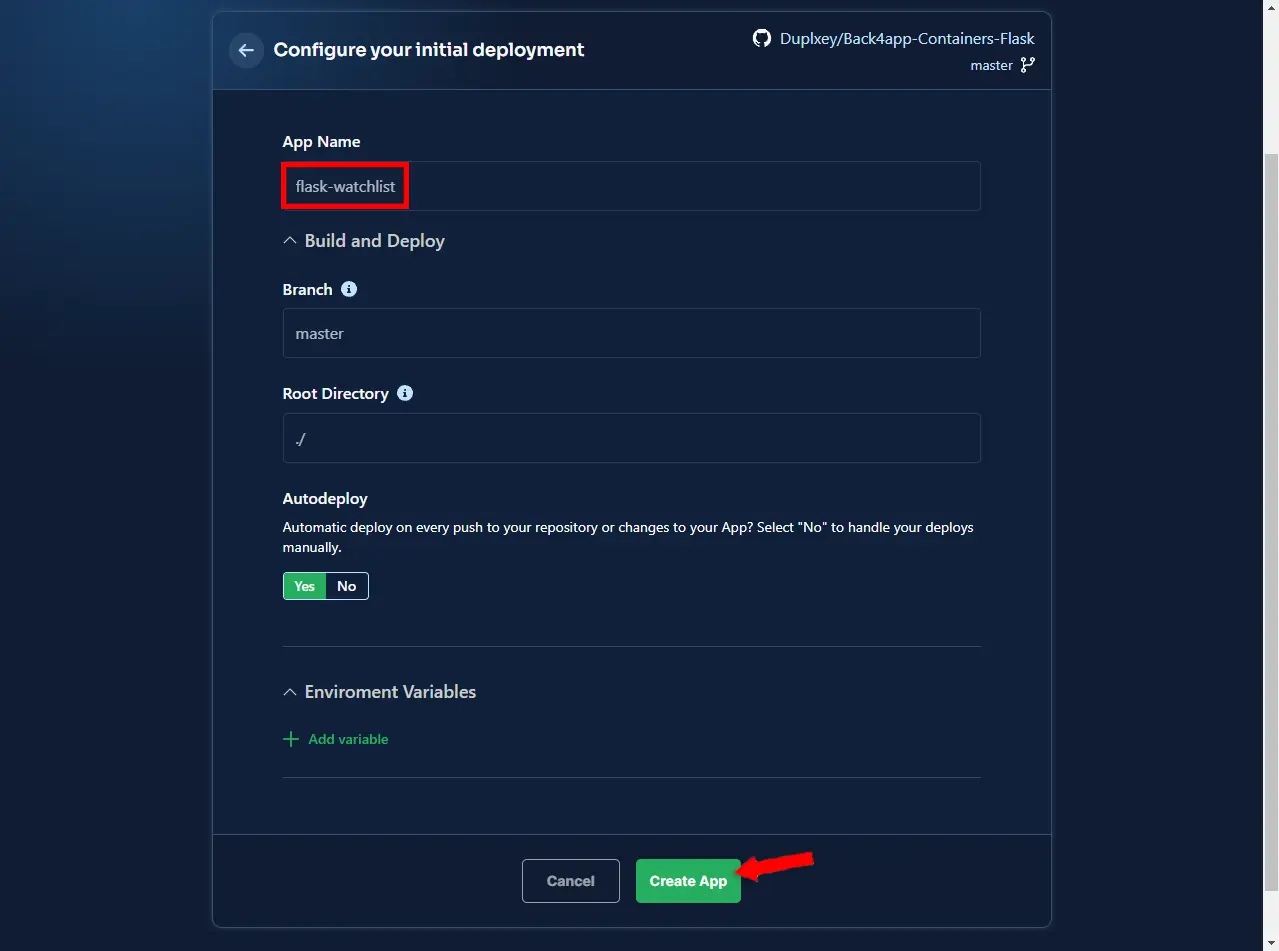
A continuación, Back4app le pedirá que configure el entorno. Elija un nombre de aplicación, yo elegiré la lista de seguimiento de flask. Siéntase libre de dejar todo lo demás como predeterminado.
Por último, haga clic en “Crear aplicación” para crear automáticamente la aplicación e implementarla.
Luego será redirigido a los detalles de su aplicación, donde podrá ver los registros de implementación.
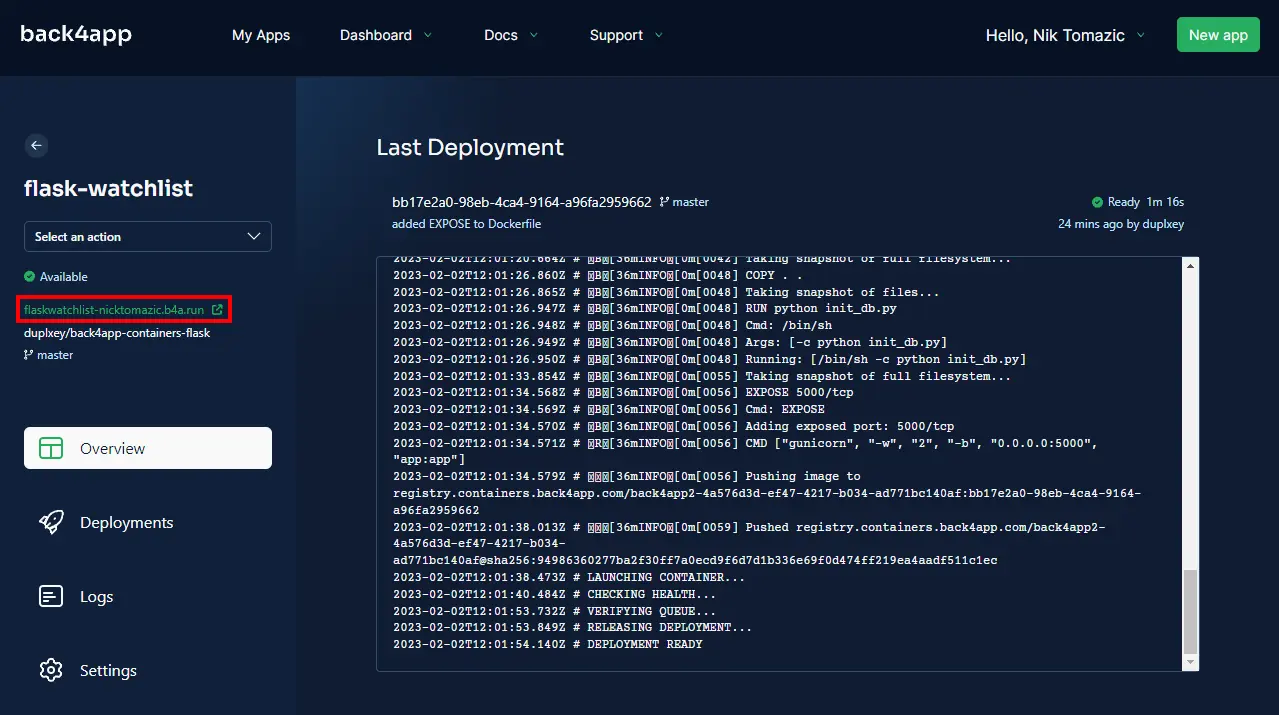
Espere unos minutos para que la aplicación se implemente y ¡listo! Su aplicación ahora está activa en Back4app Containers. Para ver su aplicación en acción, haga clic en la URL verde que se muestra a la izquierda.
Conclusión
A lo largo del artículo, explicamos qué son los contenedores, sus beneficios y demostramos cómo puede implementar contenedores en su flujo de trabajo. A estas alturas, debería poder crear su propia API REST simple, dockerizarla e implementarla en Back4app Containers.
Tome el código fuente final del repositorio de GitHub.
Pasos futuros
- No debe almacenar la base de datos en su imagen. Por el momento, cada redespliegue restablecerá la base de datos. Considere cambiar a una instancia administrada de PostgreSQL o MySQL.
- Obtenga información sobre compilaciones de varias etapas para optimizar sus Dockerfiles.
- Lea el artículo Implementación de contenedores Docker para obtener un tutorial paso a paso
Preguntas frecuentes
¿Qué es un contenedor?
Un contenedor es un paquete ejecutable independiente que incluye todo lo necesario para ejecutar la aplicación. Eso es código, tiempo de ejecución, bibliotecas, variables de entorno y archivos de configuración.
¿Cuáles son los beneficios de usar contenedores?
– Eficiencia
– Aislamiento de aplicaciones
– Separación de responsabilidades
– Desarrollo de aplicaciones más rápido
¿Cuál es la diferencia entre contenedores y máquinas virtuales?
Las máquinas virtuales son una abstracción del hardware físico, mientras que los contenedores se virtualizan a nivel del sistema operativo. Las máquinas virtuales ofrecen mayor aislamiento y seguridad, mientras que los contenedores no ocupan mucho espacio y son eficientes y escalables.
¿Cuál es la diferencia entre Docker y Kubernetes?
Docker nos permite empaquetar y distribuir aplicaciones dentro de contenedores, mientras que Kubernetes facilita el trabajo conjunto de varios contenedores.
¿Cómo desarrollar una aplicación utilizando una arquitectura basada en contenedores?
1. Elija un lenguaje de programación y codifique su aplicación.
2. Dockerize su aplicación con un Dockerfile o Docker Compose.
3. Cree una imagen de Docker y pruébela localmente.
4. Elija un CaaS como Back4app Containers y envíele su código.
¡Espere a que se despliegue el servicio y listo!

