Heroku é um dos principais fornecedores de Plataforma como Serviço (PaaS). PaaS é um tipo de serviço que agrega valor a desenvolvedores talentosos que não têm capital para estabelecer projetos de infraestrutura de ponta.
A falta de recursos financeiros é um fator limitante para muitos desenvolvedores porque a infraestrutura do servidor exige muito capital. No entanto, com PaaS, os desenvolvedores podem alugar a infraestrutura necessária para um projeto de desenvolvimento.
Heroku é indiscutivelmente o pioneiro da PaaS; a empresa fornece infraestrutura em nuvem e outros recursos necessários para projetos de desenvolvimento de aplicativos. A oferta do Heroku é um avanço significativo para os desenvolvedores, pois permite que eles se envolvam em projetos de desenvolvimento de aplicativos, apesar dos recursos limitados.
No entanto, muitos desenvolvedores continuam migrando para alternativas de código aberto Heroku.
O objetivo deste discurso é fazer uma análise detalhada do Firebase Backend as a Service. Discutiremos os méritos, deméritos, custos e recursos desta plataforma de back-end popular.
Além da habilidade e dedicação do desenvolvedor, outro fator que incentiva o desenvolvimento de aplicativos ricos em recursos é a plataforma. Uma das excelentes plataformas de desenvolvimento de aplicativos hoje é o Google Firebase, uma plataforma rica em recursos para a criação de aplicativos Android, iOS e baseados na web.
Embora existam plataformas mais recentes com excelentes recursos, o Firebase ainda é um dos principais concorrentes no back-end da indústria de desenvolvimento de aplicativos. Continuaremos discutindo o Firebase e o valor que ele traz para o desenvolvimento de aplicativos
Azure Time Series Gen2 é um serviço analítico de Internet das Coisas (IoT) de ponta a ponta projetado para implantações industriais de IoT. Ele fornece APIs poderosas que você pode usar para integrá-lo aos fluxos de trabalho e aplicativos atuais.
O Azure Time Series Insights coleta, processa, armazena, consulta e visualiza dados de IoT em escala, adicionando contexto e otimizando-o para análise de série temporal. Ele é projetado para explorar dados ad hoc e analisar operações, ajudando você a descobrir tendências ocultas, detectar anomalias e realizar análises de causa raiz.
Neste artigo, você aprenderá:
O que é um modelo de série temporal do Azure?
Componentes do modelo de série temporal
Armazenamento de dados de série temporal do Azure
Camadas de armazenamento e disponibilidade de dados
Loja Quente
Loja fria
Práticas recomendadas da série temporal do Azure
Usando armazenamento quente e armazenamento frio
Configurar IDs de série temporal e propriedades de carimbo de data / hora
Otimize seus eventos
Alta disponibilidade
O que é um modelo de série temporal do Azure?
Um Modelo de Série Temporal é uma entidade central na Série Temporal do Azure, que permite gerenciar, manter e aprimorar conjuntos de dados de série temporal para análise.
O modelo de série temporal oferece os seguintes recursos:
Crie e gerencie cálculos e fórmulas usando funções escalares e operações agregadas
Defina relacionamentos hierárquicos para permitir pesquisa, referência cruzada e navegação
Defina propriedades associadas a instâncias de dados e use-as para construir hierarquias
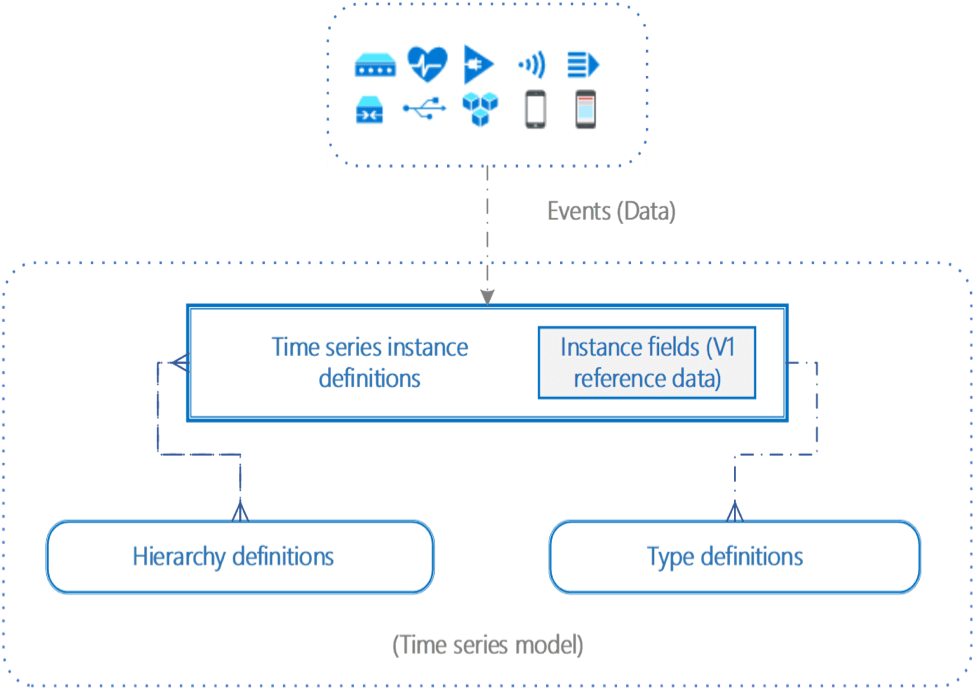
Componentes do modelo de série temporal
Um modelo de série temporal tem três componentes principais: instâncias, hierarquias e tipos. Você usa esses componentes para especificar um modelo para análise de dados de série temporal e organizar os dados.
Uma instância do modelo de série temporal é uma série temporal individual. Ele possui um identificador exclusivo, o ID da série temporal, que normalmente é o ID do ativo ou dispositivo que gerou os dados.
Cada instância pode ser descrita por propriedades adicionais, como tipo, descrição, nome, hierarquias e campos de instância. Os campos de instância são coleções de informações como nível de hierarquia, operador de dispositivo, fabricantes e muito mais.
Assim que você adiciona uma fonte de evento no Azure Time Series Insights, o sistema descobre a série temporal e cria Modelos de Série Temporal. Você pode atualizar esses modelos ou criar novos usando consultas de modelo de série temporal.
Hierarquias
O modelo de série temporal organiza instâncias especificando nomes de atributos e relacionamentos hierárquicos entre eles. Uma instância pode ser mapeada para uma hierarquia ou várias hierarquias – veja um exemplo abaixo.
Os tipos de modelo de série temporal são associados a uma instância específica e permitem definir variáveis ou expressões usadas para realizar cálculos.
Os tipos podem ter uma ou mais variáveis. Por exemplo, uma instância do Modelo de série temporal pode ter o tipo de sensor de temperatura, consistindo em variáveis de temperatura média, temperatura mínima e temperatura máxima.
Armazenamento de dados de série temporal do Azure
O Azure Time Series Insights funciona em conjuntos de dados armazenados em sua conta de Armazenamento do Azure. Aqui estão algumas considerações importantes para armazenar conjuntos de dados de série temporal no Azure.
Camadas de armazenamento e disponibilidade de dados
O Azure Time Series Insights Gen2 divide e indexa dados para otimizar o desempenho da consulta. Depois de indexar os dados, você pode consultar os dados do armazenamento quente (se habilitado) e do armazenamento frio.
A quantidade de dados capturados e a velocidade de processamento de cada partição afetam a disponibilidade. Você pode configurar alertas para serem notificados quando o processamento de dados estiver atrasado em seu ambiente.
Loja Quente
Você pode acessar dados de armazenamento ativo por meio da API de consulta de série temporal, do TSI Explorer do Time Series Insight ou do conector do Power BI. As consultas de armazenamento ativo são gratuitas e não têm cota, mas você pode realizar até 30 solicitações simultâneas.
Quando o armazenamento de dados quente está ativado, funciona da seguinte maneira:
Sugere todos os dados – se o armazenamento a quente estiver habilitado, todos os dados que fluem para o ambiente são roteados para ele, independentemente dos carimbos de data / hora do evento. O pipeline de streaming é desenvolvido para streaming quase em tempo real e não oferece suporte à coleta de eventos anteriores.
Período de retenção – calculado com base na data e hora em que o evento foi indexado no armazenamento aquecido, não no carimbo de data / hora do evento.
Sem back-fill – se você habilitar o armazenamento quente em um ambiente existente que já tenha dados no armazenamento frio, os dados não serão preenchidos novamente no armazenamento quente.
Loja fria
Para eventos enviados para armazenamento frio, o Azure Time Series Insight Gen2 mantém até duas cópias de cada evento na conta de Armazenamento do Azure. Os eventos são armazenados em ordem cronológica. Com o tempo, o Azure Time Series Insights Gen2 reparticiona seus dados para otimizar as consultas de alto desempenho. Os dados são armazenados na conta de armazenamento do Azure indefinidamente.
Práticas recomendadas da série temporal do Azure
Monitore o Azure Time Series Insights
A Série Temporal do Azure pode ser uma parte crítica dos pipelines de dados IIoT. É importante configurar o monitoramento, para garantir que o serviço está funcionando corretamente, identificar problemas e resolvê-los. Você pode usar o Azure Monitor para realizar o monitoramento contínuo do Azure Time Series Insights.
Concentre-se em métricas, como bytes recebidos de todas as fontes de eventos, bytes processados com êxito e bytes disponíveis para processamento. Observe também a tabela TSIIngress, que mostra os erros que ocorrem no pipeline de entrada do evento.
Usando armazenamento quente e armazenamento frio
Você pode escolher habilitar um “armazenamento aquecido”, que permite tempos de resposta mais rápidos e fornece um período de retenção de 7 a 30 dias. Observe que os dados que precisam ser retidos por mais de 30 dias são fornecidos pela “loja fria” e incorrem em uma taxa de acesso aos dados. A análise interativa de dados recentes deve residir no armazenamento aquecido, enquanto as tendências de longo prazo e a análise de padrões devem residir no armazenamento frio.
Configurar IDs de série temporal e propriedades de carimbo de data / hora
No Azure Time Series, você precisa selecionar uma ID e três chaves para cada série temporal, que pode ser usada posteriormente para particionar os dados. Você também deve designar uma propriedade de carimbo de data / hora ao adicionar fontes de eventos para rastreamento futuro. Caso contrário, o tempo de enquing do evento será usado como seu registro de data e hora. Além disso, observe que os valores de carimbo de data / hora fazem distinção entre maiúsculas e minúsculas e devem ser formatados de acordo com as especificações individuais da origem do evento.
Otimize seus eventos
Certifique-se de que os eventos sejam otimizados antes de enviá-los ao Azure Time Series Insights. Recomenda-se desnormalizar os eventos antes de ingeri-los. Você deve armazenar metadados em seu modelo de série temporal e garantir que os campos e eventos da instância contenham apenas informações vitais, como ID da série temporal e a propriedade timestamp.
Alta disponibilidade
O Time Series Insights alavanca redundâncias em nível de região para alta disponibilidade. Você pode executar a recuperação de desastres no Azure usando o Azure Site Recovery (ASR). Outros recursos incluem replicação geográfica e balanceamento de carga para failover, recuperação de dados e backup de VMs locais ou baseadas no Azure usando o serviço de Backup do Azure.
Para garantir que seus dispositivos e usuários tenham alta disponibilidade global entre regiões, certifique-se de habilitar os recursos corretos do Azure.
Conclusão
Este artigo explicou sobre os componentes, armazenamento e práticas recomendadas do Azure Time Series Insights que podem ajudá-lo a obter insights de dados de série temporal de IoT na nuvem.
FAQ
O que é o Azure Time Series Insights?
Azure Time Series Gen2 é um serviço analítico de Internet das Coisas (IoT) de ponta a ponta projetado para implantações industriais de IoT. Ele fornece APIs poderosas que você pode usar para integrá-lo aos fluxos de trabalho e aplicativos atuais.
O que é um modelo de série temporal do Azure?
Um Modelo de Série Temporal é uma entidade central na Série Temporal do Azure, que permite gerenciar, manter e aprimorar conjuntos de dados de série temporal para análise.
Quais são os componentes do modelo de série temporal?
Como o desenvolvimento de software está ficando complexo a cada dia que passa, os serviços e tecnologias de back-end estão se tornando mais cruciais. É porque eles determinarão os recursos e o desempenho de seu projeto.
O escopo é o seu projeto, e suas aplicações na vida real não importam se é uma startup ou um grande projeto. O mais importante é a tecnologia de back-end.
Os motivos para essa importância são diversos, sendo um deles a maior confiabilidade quanto à necessidade dessa aplicação. Além disso, uma boa tecnologia de back-end pode garantir que seu software terá os seguintes recursos.
Escalabilidade
Desempenho
Capacidade de resposta
A seleção da tecnologia de back-end certa é uma parte vital quando se trata de desenvolvimento de software. No entanto, a abundância de tecnologias de back-end presentes no mundo torna muito difícil para gerentes ou desenvolvedores selecionar a melhor.
Outra razão para isso é que cada um deles possui suas diferentes características e benefícios que aumentam a confusão. Acredite ou não, mas neste caso, as coisas ficam complicadas quando você não é um desenvolvedor.
Como selecionar a tecnologia de back-end certa é muito importante, discutiremos aqui as dez melhores tecnologias de back-end. Esperamos que esta discussão detalhada sobre as melhores tecnologias de back-end o ajude a selecionar a melhor para suas necessidades.
O desenvolvimento de aplicativos modernos depende de tecnologias de back-end para construir, executar e gerenciar aplicativos. Os back-ends são tão essenciais para projetos de desenvolvimento de aplicativos que selecionar o errado pode causar gargalos nas atribuições de desenvolvimento. Portanto, os proprietários de negócios e desenvolvedores devem reservar um tempo para escolher a tecnologia de back-end apropriada para aprimorar a execução perfeita do projeto.
Selecionar a tecnologia de back-end certa permite que os desenvolvedores trabalhem mais rápido, escalem aplicativos rapidamente e criem aplicativos de qualidade. Pesquisar o back-end adequado pode ser desafiador porque há muitas opções no mercado. Este artigo o ajuda a explorar as opções de back-end adequadas mais rapidamente, revisando as dez principais linguagens de programação de back-end.
Antes de começarmos a revisar essas tecnologias, vamos dar uma breve visão geral dos back-ends de aplicativos.
Neste artigo, daremos uma visão geral da tecnologia de back-end para analisar como ela funciona.
O que é um backend?
O backend é a parte de um aplicativo que executa várias tarefas para as quais o aplicativo foi projetado. O back-end de um aplicativo é gerenciado pelo administrador e inacessível para o usuário do aplicativo; é a parte de um aplicativo que armazena dados e códigos que interpretam as sintaxes do programa.
O backend contrasta diretamente com o front-end que fornece uma interface, permitindo que o usuário interaja com o back-end do aplicativo.
Na maioria das vezes, os códigos de backend consistem em várias linguagens de programação. Freqüentemente, é chamada de camada de acesso a dados porque contém as funções acessíveis a programas clientes e usuários para fornecer vários serviços.
Conceitos de vitais de um backend
O backend consiste em várias camadas. É necessário discutir a arquitetura de back-ends para entender as camadas integrais que ela contém. Abaixo estão alguns componentes principais de uma arquitetura de back-end.
Banco de Dados
O banco de dados é um local central para armazenar dados em um formato exclusivo e recuperá-los quando necessário. O banco de dados fornece funções para acessar, adicionar, excluir e atualizar dados por um usuário privilegiado. Um exemplo típico é uma biblioteca que possui diferentes seções e subseções que contêm livros.
Servidor Virtual
Isso se refere a um servidor localizado em outra máquina servidora física. Este tipo de servidor possui um sistema operacional e recursos de servidor alocados. Suas operações e funções são independentes de outras máquinas virtuais.
Uma única máquina servidora pode conter vários servidores virtuais. Talvez, a melhor parte de um servidor virtual é que ele não tem interação com a máquina do servidor host. Em essência, os aplicativos executados no ambiente de servidor virtual são segregados e seguros.
Container
Os contêineres executam as mesmas funções que uma máquina virtual, exceto pelo fato de não executarem um sistema operacional dedicado. Em vez disso, vários contêineres podem compartilhar o mesmo sistema operacional. O fato de um contêiner não hospedar um sistema operacional o torna leve e mais rápido do que um servidor virtual.
Os contêineres são como sistemas operacionais dedicados à execução de processos específicos. Eles são excelentes para executar aplicativos e outros microprocessos.
Requisição de API
As solicitações de API referem-se a chamadas de dados iniciadas pelo servidor inserindo uma URL específica em um aplicativo cliente.
Load Balancer
Os backends possuem um recurso que distribui cargas entre os servidores back-end disponíveis para aprimorar a entrega de serviços aos terminais clientes. Esse recurso é chamado de balanceador de carga; evita que um único servidor fique sobrecarregado por solicitações de clientes para que os aplicativos continuem a funcionar de maneira ideal. Este recurso também pode adicionar servidores sob demanda quando os servidores disponíveis não podem controlar o tráfego de terminais de clientes.
A arquitetura de um backend
Olhando mais de perto a arquitetura de backend, você perceberá que eles são separados em três segmentos chamados camadas de back-end. Vamos dar uma olhada nessas camadas, uma após a outra.
Servidores de Bases de Dados
A camada de banco de dados é a primeira camada no backend. É essencial observar que a camada de banco de dados pode conter vários servidores que podem funcionar como replicadores de dados ou gerenciar rotinas de backup.
Na maioria das vezes, os bancos de dados são projetados como infraestruturas redundantes com pelo menos dois bancos de dados que sincronizam dados em tempo real. Os servidores de banco de dados trabalham juntos para garantir que os dados estejam sempre disponíveis, apesar das contingências.
Servidores de Aplicação
A segunda camada consiste em várias máquinas virtuais que processam solicitações de dispositivos clientes. O número de máquinas virtuais disponíveis varia ao longo do dia por meio de uma tecnologia chamada escalonamento automático para alocar o número ideal de máquinas virtuais para lidar com o tráfego de terminais de cliente conectados.
Os servidores virtuais podem ter vários contêineres, enquanto cada contêiner pode hospedar apenas um único aplicativo.
Conexão de rede
A camada que conecta o aplicativo à Internet é a terceira e última camada. Essa camada garante que o desempenho do aplicativo seja ideal por meio de balanceadores de carga e redes de entrega de conteúdo (CDNs). Quando um aplicativo apresenta baixa latência, a falha pode ser rastreada até a camada de conexão de rede.
Conclusão
Este artigo fornece uma visão geral dos back-ends e como eles funcionam para fornecer uma plataforma estável para hospedar aplicativos. Conceitos básicos de back-end, como bancos de dados escalonáveis, contêineres, servidores virtuais, balanceadores de carga e CDNs foram explicados.
Aqui discutimos toda a arquitetura e funcionamento de um back-end. Todos esses elementos trabalham juntos para fornecer back-ends para o desenvolvimento e hospedagem de aplicativos.
FAQ
O que é um backend?
O backend é a parte de um aplicativo que executa várias tarefas para as quais o aplicativo foi projetado. O back-end de um aplicativo é gerenciado pelo administrador e inacessível para o usuário do aplicativo; é a parte de um aplicativo que armazena dados e códigos que interpretam as sintaxes do programa.
Como é a arquitetura de um backend?
– Servidores de banco de dados – Servidores de aplicação – Conexão de rede
Quais são os conceitos vitais de backend?
– Base de dados – Máquina virtual – Container – Solicitação de API – Balanceador de carga
Seja no desenvolvimento de aplicativos ou no gerenciamento do aplicativo desenvolvido após a implantação, fica difícil para os desenvolvedores gerenciar coisas como conexões de servidor e gerenciamento de dados em toda a comunidade de usuários. Não é fácil devido à complexidade da tarefa, mas é muito demorado.
Uma das melhores soluções para os desenvolvedores é usar algumas ferramentas ou plataformas que fornecem seus serviços para o back-end. Aqui, discutiremos o Pusher e algumas das melhores plataformas alternativas que podem ser usadas no lugar do Pusher no gerenciamento e funcionalidade de dados.
React Native é uma das plataformas de desenvolvimento de aplicativos móveis mais populares e amplamente utilizadas disponíveis atualmente. Essa estrutura, criada pelo Facebook, foi adotada abertamente por inúmeras empresas ao redor do mundo.
Os recursos e a funcionalidade que ele oferece ajudam as empresas a oferecer experiências uniformes e fluidas na web, plataformas iOS e Android. Muitas empresas importantes também estão usando o React Native para suas necessidades de desenvolvimento. Dê uma olhada na lista das principais empresas que usam a estrutura abaixo.
Engine Yard é uma das principais soluções de PaaS destinada a configurar, implantar e automatizar aplicativos em um ambiente de nuvem. É um software robusto de gerenciamento de aplicativos baseado em nuvem criado para capacitar desenvolvedores e DevOps a monitorar, controlar e provisionar aplicativos em nuvem.
O Engine Yard pode oferecer excelente controle e escolha juntos, junto com suporte especializado. Ele pode permitir que os usuários se concentrem mais na criação de aplicativos sem gastar muito tempo na instalação do sistema operacional, configurações de plataforma e gerenciamento de suas atualizações.
Esta ferramenta está sendo usada para permitir que os usuários aproveitem a essência da computação em nuvem sem o incômodo de serem responsáveis pelo gerenciamento da operação.
No geral, é uma solução confiável para os desenvolvedores que usam Ruby on Rails, Node.js e gerenciamento e implantação de PHP. Quer seja uma implantação de grande ou pequena escala, a Engine Yard é capaz de fornecer a você todas as ferramentas essenciais para garantir implantações rápidas, profundo conhecimento e alta escalabilidade.
Ainda mais, ele também permite que seus consumidores mantenham o controle geral do aplicativo. Alguns dos principais recursos do Engine Yard são balanceamento de carga, clonagem, replicação de dados e backups.
O Google App Engine e o Firebase são back-ends populares para o desenvolvimento de aplicativos ágeis e de alto desempenho. Existem prós e contras em usar cada um e a escolha depende de suas necessidades. Dê uma olhada detalhada em ambas as plataformas de back-end abaixo.