Azure Time Series Gen2 est un service d’analyse de l’Internet des objets (IdO) de bout en bout, conçu pour les déploiements IdO industriels. Il fournit de puissantes API que vous pouvez utiliser pour l’intégrer aux flux de travail et applications actuels.
Azure Time Series Insights collecte, traite, stocke, interroge et visualise les données IdO à l’échelle, en ajoutant du contexte et en les optimisant pour l’analyse des séries chronologiques. Il est conçu pour explorer les données ad hoc et analyser les opérations, en vous aidant à découvrir les tendances cachées, à repérer les anomalies et à effectuer une analyse des causes profondes.
Dans cet article, vous apprendrez :
- Qu’est-ce qu’un modèle de série chronologique Azure ?
- Composants du modèle de série chronologique
- Stockage des données de séries chronologiques sur Azure
- Niveaux de stockage et disponibilité des données
- Boutique chaude
- Boutique froide
- Meilleures pratiques pour les séries chronologiques Azure
- Utilisation de la boutique chaude et froide
- Configuration des ID de séries chronologiques et des propriétés d’horodatage
- Optimisez vos événements
- Disponibilité élevée
Qu’est-ce qu’un modèle de série chronologique Azure ?
Un modèle de série chronologique est une entité centrale dans Azure Time Series, qui vous permet de gérer, de maintenir et d’améliorer les ensembles de données de série chronologique pour l’analyse.
Le modèle de série chronologique offre les capacités suivantes :
- Créer et gérer des calculs et des formules en utilisant des fonctions scalaires et des opérations d’agrégation.
- Définir les relations hiérarchiques pour permettre la recherche, les références croisées et la navigation.
- Définir les propriétés associées aux instances de données et les utiliser pour construire des hiérarchies.
Composants du modèle de série chronologique
Un modèle de série temporelle comporte trois éléments clés : les instances, les hiérarchies et les types. Vous utilisez ces composants pour spécifier un modèle d’analyse des données de séries chronologiques et organiser les données.
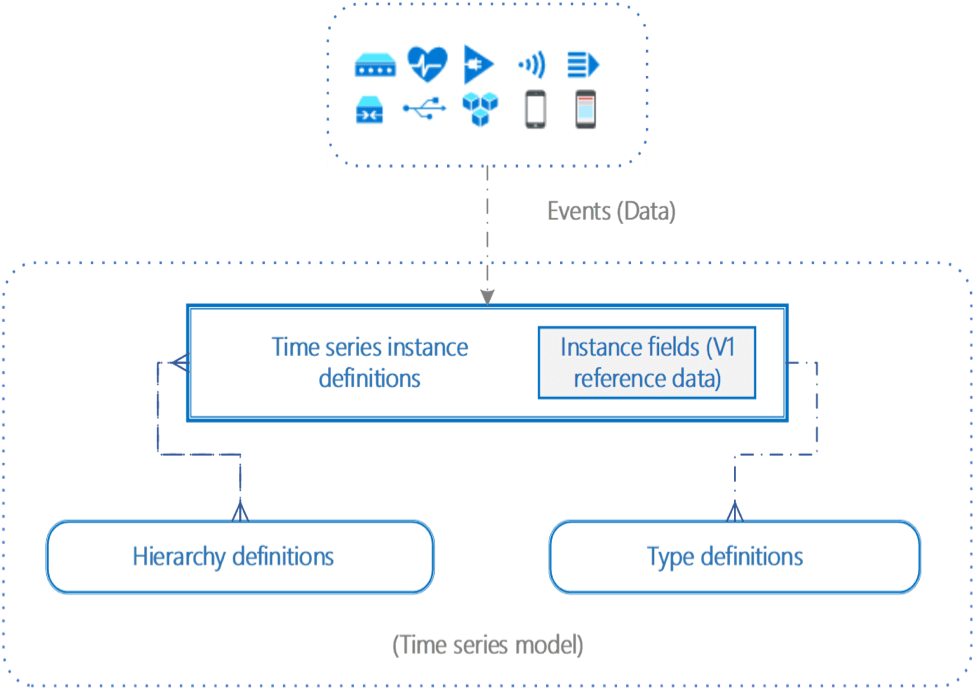
Source: Azure
Instances
Une instance de modèle de série chronologique est une série chronologique individuelle. Elle possède un identifiant unique, l’ID de la série chronologique, qui est généralement l’ID de l’actif ou du dispositif qui a généré les données.
Chaque instance peut être décrite par des propriétés supplémentaires, telles que le type, la description, le nom, les hiérarchies et les champs d’instance. Les champs d’instance sont des collections d’informations telles que le niveau hiérarchique, l’opérateur du dispositif, les fabricants, etc.
Dès que vous ajoutez une source d’événements dans Azure Time Series Insights, le système découvre les séries chronologiques et crée des modèles de séries chronologiques. Vous pouvez mettre à jour ces modèles ou en créer de nouveaux à l’aide de requêtes de modèles de séries chronologiques.
Hiérarchies
Le modèle de série chronologique organise les instances en spécifiant les noms des attributs et les relations hiérarchiques entre eux. Une instance peut correspondre à une ou plusieurs hiérarchies – voir l’exemple ci-dessous.
Source: Azure
Types
Les types de modèles de séries temporelles sont associés à une instance spécifique, et vous permettent de définir des variables ou des expressions utilisées pour effectuer des calculs.
Les types peuvent avoir une ou plusieurs variables. Par exemple, une instance de modèle de série temporelle pourrait avoir un type de capteur de température, composé de variables de température moyenne, de température minimale et de température maximale.
Stockage des données de séries chronologiques sur Azure
Azure Time Series Insights fonctionne sur les ensembles de données stockés dans votre compte Azure Storage. Voici quelques considérations clés pour le stockage des ensembles de données de séries chronologiques dans Azure.
Niveaux de stockage et disponibilité des données
Azure Time Series Insights Gen2 partitionne et indexe les données, afin d’optimiser les performances des requêtes. Après avoir indexé les données, vous pouvez interroger les données du stockage à chaud (si activé) et du stockage à froid.
La quantité de données capturées et la vitesse de traitement de chaque partition influent sur la disponibilité. Vous pouvez configurer des alertes pour être informé lorsque le traitement des données est en retard dans votre environnement.
Boutique chaude
Vous pouvez accéder aux données du stockage à chaud par le biais de l’API Time Series Query, de l’explorateur TSI Time Series Insight ou du connecteur Power BI. Les requêtes de stockage à chaud sont gratuites et n’ont pas de quota, mais vous pouvez effectuer jusqu’à 30 requêtes simultanées.
Lorsque le stockage à chaud des données est activé, il fonctionne comme suit :
- Intégration de toutes les données – si le stockage à chaud est activé, toutes les données qui entrent dans l’environnement y sont acheminées, indépendamment de l’horodatage des événements. Le pipeline de streaming est construit pour le streaming en temps quasi réel et ne prend pas en charge la collecte d’événements passés.
- Période de rétention – calculée en fonction de la date et de l’heure auxquelles l’événement a été indexé dans le stockage à chaud, et non de l’horodatage de l’événement.
- Pas de remplissage – si vous activez le stockage à chaud dans un environnement existant qui a déjà des données dans le stockage à froid, les données ne seront pas repeuplées dans le stockage à chaud.
Boutique froide
Pour les événements envoyés au stockage à froid, Azure Time Series Insight Gen2 conserve jusqu’à deux copies de chaque événement dans le compte Azure Storage. Les événements sont stockés dans l’ordre chronologique. Au fil du temps, Azure Time Series Insights Gen2 répartit vos données pour optimiser les requêtes hautes performances. Les données sont stockées indéfiniment dans le compte de stockage Azure.
Meilleures pratiques pour les séries chronologiques Azure
Surveiller Azure Time Series Insights
Azure Time Series peut constituer un élément essentiel des pipelines de données IdO. Il est important de mettre en place un suivi, pour s’assurer que le service fonctionne correctement, identifier les problèmes et les résoudre. Vous pouvez utiliser Azure Monitor pour effectuer une surveillance continue d’Azure Time Series Insights.
Concentrez-vous sur des mesures telles que les octets reçus de toutes les sources d’événements, les octets traités avec succès et les octets disponibles pour le traitement. Observez également le tableau TSIIngress, qui indique les erreurs qui se produisent dans le pipeline d’entrée des événements.
Utilisation de la boutique chaude et froide
Vous pouvez choisir d’activer un « stockage à chaud », qui permet des temps de réponse plus rapides et offre une période de conservation de 7 à 30 jours. Notez que les données qui doivent être conservées pendant plus de 30 jours sont servies à partir de la « mémoire froide » et que l’accès aux données est payant. Les analyses interactives sur des données récentes doivent être stockées à chaud, tandis que les tendances à long terme et l’analyse des modèles doivent être stockées à froid.
Configuration des ID de séries chronologiques et des propriétés d’horodatage
Dans Azure Time Series, vous devez sélectionner un ID et trois clés pour chaque série temporelle, que vous pourrez utiliser ultérieurement pour partitionner les données. Vous devez également désigner une propriété d’horodatage lorsque vous ajoutez des sources d’événements pour un suivi ultérieur. Sinon, l’heure d’interrogation de l’événement sera utilisée comme horodatage. Notez également que les valeurs d’horodatage sont sensibles à la casse et qu’elles doivent être formatées selon les spécifications de la source de l’événement.
Optimisez vos événements
Assurez-vous que les événements sont optimisés avant de les envoyer à Azure Time Series Insights. Il est recommandé de dénormaliser les événements avant de les ingérer. Vous devez stocker les métadonnées dans votre modèle de série chronologique et vous assurer que les champs d’instance et les événements ne contiennent que des informations essentielles, comme l’ID de la série chronologique et la propriété timestamp.
Disponibilité élevée
Time Series Insights exploite les redondances au niveau régional pour assurer une haute disponibilité. Vous pouvez effectuer une reprise après sinistre dans Azure en utilisant Azure Site Recovery (ASR). Parmi les autres fonctionnalités figurent la géo-réplication et l’équilibrage de charge pour le basculement, la récupération des données et la sauvegarde des VM sur site ou basées sur Azure à l’aide du service Azure Backup.
Pour que vos appareils et vos utilisateurs bénéficient d’une haute disponibilité globale et interrégionale, assurez-vous d’activer les fonctions Azure appropriées.
Conclusion
Cet article explique les composants, le stockage et les meilleures pratiques d’Azure Time Series Insights qui peuvent vous aider à tirer des enseignements des données de séries chronologiques IdO dans le cloud.
FAQ
Qu’est-ce qu’Azure Time Series Insights ?
Azure Time Series Gen2 est un service d’analyse de l’Internet des objets (IdO) de bout en bout, conçu pour les déploiements IdO industriels. Il fournit de puissantes API que vous pouvez utiliser pour l’intégrer aux flux de travail et applications actuels.
Qu’est-ce qu’un modèle de série chronologique Azure ?
Un modèle de série chronologique est une entité centrale dans Azure Time Series, qui vous permet de gérer, de maintenir et d’améliorer les ensembles de données de série chronologique pour l’analyse.
Quelles sont les composantes du modèle de séries chronologiques ?
– Instances
– Hiérarchies
– Types

